

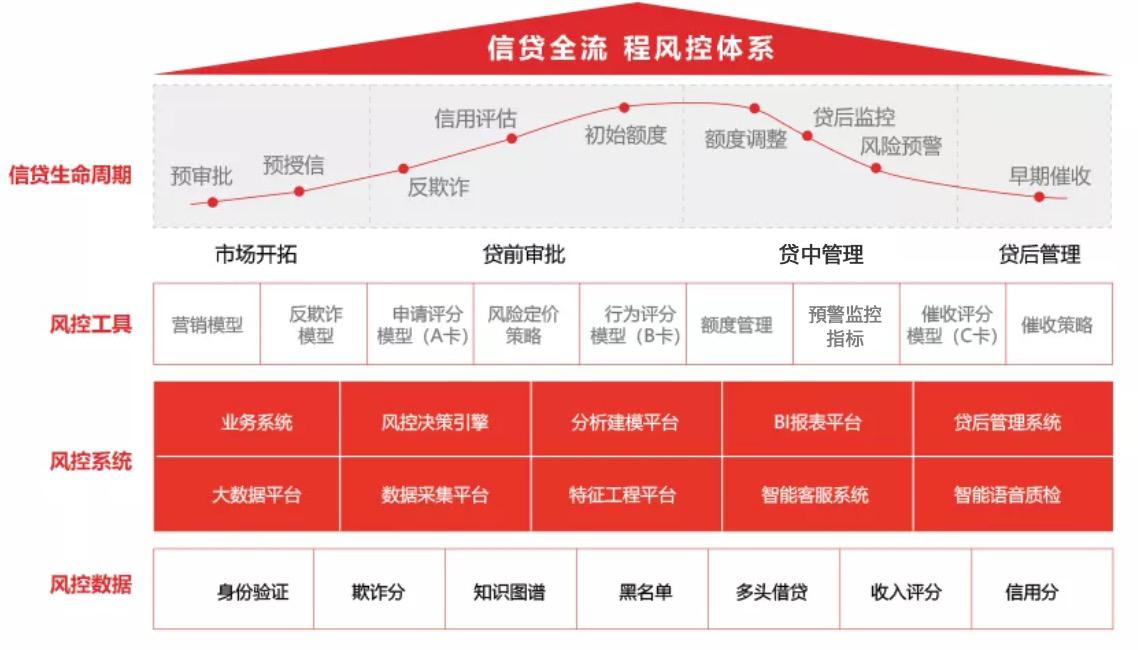

风控体系是玖富普惠网贷风险管控全流程中的核心体系。一般情况下,借款人出现信用风险,可通过风险定价策略等手段进行防范,风险可控性较大。而借款人在一开始,就以骗贷为目的进行借贷并且借款成功,则出借人会承受相当比例的损失。因此风控体系主要考虑两大类风险:一类是信用风险,一类是欺诈风险。
风险人群中很少能自然地找出几类在业务上具有显著差异的人群,可以人为分类,但是类和类之间往往是没有清晰边界的。因此风控场景下的建模多为分类算法模型,实际上做的事情往往是给出用户违约的预测概率,对各种风险场景有个统一的量化评估。模型设计的目的就是把好样本和坏样本尽可能区分出来。搭建风控分类模型通常有两类算法:

传统评分卡(logistic regression)
传统评分卡一直在银行信贷业务中成功实践了几十年,其优势在于:泛化性强,稳定性好,线性模型可解释性强。少样本就可以训练模型。其劣势在于:特征要求强相关,线性特征对于挖掘的信息价值相对有限,模型效果相当若与机器学习算法。

机器学习风险模型(Machine Learning)
随着大数据的出现,机器学习慢慢焕发出其生命力,如Random Forest、GBDT、XGBoost、LightGBM等集成学习方法在风险模型中得到广泛应用,可以通过集成学习将弱分类器打造出强分类模型。其优势在于:引入了非线性因素,模型拟合能力更强;支持更多弱特征入模,而不必像评分卡模型需要花大量时间筛选特征。而其劣势在于:由于引入了大量的非线性因素,模型可解释性降低;容易产生过拟合现象,泛化能力下降。

大数据是风控的基础,做风险评分模型这个项目前,先得积累足够多的数据(样本和特征),不然真是巧妇难为无米之炊。对借款人全方位的理解,一般可将风控数据分为四部分,自上而下,这些数据与逾期信用风险的相关性逐渐降低。通常,我们也称为强金融属性和弱金融属性数据。
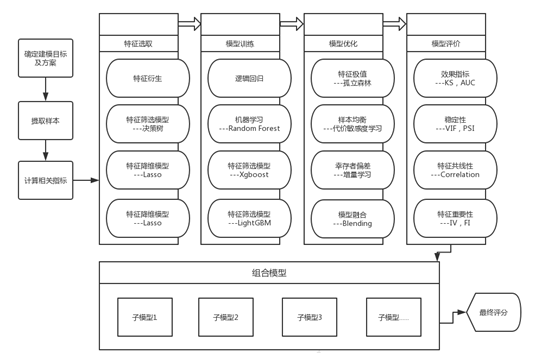
使用上述数据,采用传统逻辑回归和XGBOOST等机器学习多样化的技术方法进行模型开发,采用最先进的算法组合选择,确定最终决策模型。同时线上采用冠军和挑战者模型策略进行比较优化。下表为完整建模流程和使用的技术:
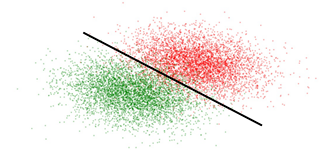
风险模型是一个概率模型,一般是希望求出一个和真实概率分布最接近的概率分布函数,而不是寻找一条干净的边界把人群分为两类。在对风险人群建模的时候,人群在空间中是连续的,人群的标签由一随机事件决定。人群样本在空间中是一片连续的点云,不同位置的云代表了采集到的不同的人群信息,不同的人群有不同的逾期概率,概率随空间的变换是连续的。但为了直观易于理解,我们用下面的二维图对建模原理做出解释。如示意图红色代表坏样本,绿色代表未好样本,黑色直线代表模型分类器。可以直观的看出,分类器很难100%对好坏样本做出区分,总有部分样本因为分类器的局限性导致对样本的判断错误,这也就是为什么坏用户会被放进来的原因。另外,距离分类器越远的样本越纯,越近则约混淆。当然,越好的模型生成的分类器对用户判断越准确,从而降低整体分类空间的坏用户比例。
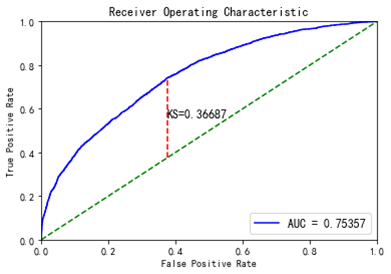
在评估模型效果的时候,通常使用AUC,KS这样的描述总体区分度指标。下图表示的是KS和AUC的示意图,通常KS>0.2的模型即可使用,KS>0.3的模型就是一个不错的模型了。
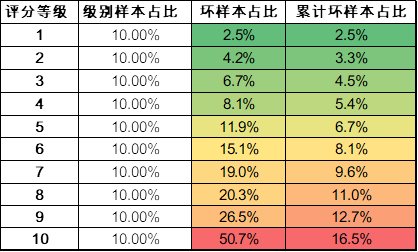
根据开发出来的评分模型,我们对验证样本做打分预测,其评分等级分布如下表和图。评分等级越高,则该等级的坏样本占比越少。模型分类器的区分能力越强,其不同等级坏占比所形成的斜率就越大,但很难实现好的评分等级的用户没有坏样本。因此风险模型与经过数据挖掘的风险政策相结合,可以进一步提升风控系统对风险的判断能力,从而达到风险收益和用户成本的平衡。如下表所示:我们的评分模型有很好的区分度,最高等级的坏样本占比仅为最低等级的1/25。
北京玖富普惠信息技术有限公司
京ICP备16046424号-1  京公网安备 11010502034176号 营业执照
京公网安备 11010502034176号 营业执照
